
Einen ganz besonderen AHA Moment hatte ich kürzlich in einem Workshop bei Udi Dahan, CEO von Particular. In seinem Beispiel ging es um die klassische Entität eines Kunden.
Microservices zu realisieren bedeutet Fachlichkeiten sauber schneiden und in eigenständige Silos (oder Säulen) packen zu müssen. Jedes Silo muss dabei die Hohheit über die eigenen Daten besitzen, auf denen es die zugehörigen Geschäftsprozesse abbildet. Soweit so gut. Doch wie lässt sich dies im Falle eines Kunden bewerkstelligen, der klassischerweise wie im Screenshot zu sehen modelliert ist? Unterschiedliche Eigenschaften werden von unterschiedlichen Microservices benötigt bzw. verändert.
Wird die gleiche Entität in allen Silos verwendet, muss es eine entsprechende Synchronisierung zw. den Microservices geben. Das hat erhelbiche Auswirkungen auf Skalierbarkeit und Performance. In einer Applikation mit häufig parallelen Änderungen an einer Entität wird das Fehlschlagen von Geschäftsprozessen zunehmen – oder im schlimmsten Fall zu Inkonsistenzen führen.
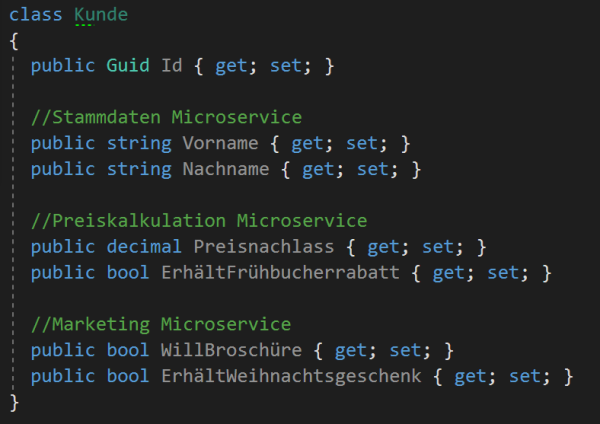
Klassische Kundeentität
Udi schlägt die folgende Modellierung vor:

Der Kunde wird durch unabhängige Entitäten modelliert
Zur Identifikation, welche Daten zusammengehören, schlägt Udi einen Interessanten Ansatz vor:
Fragt die Fachabteilung, ob das Ändern einer Eigenschaft Auswirkung auf eine andere Eigenschaft hat.
Würde das Ändern des Nachnamens einen Einfluss auf die Preiskalkulation haben? Oder auf die Art der Marketings?
Nun gilt es noch das Problem der Aggregation zu lösen, sprich wenn ich in meiner Anzeige unterschiedliche Daten unterschiedlicher Microserivces anzeigen möchte. Klassischerweise würde es jetzt eine Tabelle geben, die die Spalten
| ID_Kunde | ID_Kundenstamm | ID_Bestandskundenmarketing | ID_Preiskalkulation |
besitzt. Das führt aber zu 2 Problemen:
- Die Tabelle muss immer erweitert werden, wenn ein neuer Microservices hinzugefügt wird.
- Sofern ein Microservices die gleiche Funktionalität in Form unterschiedlicher Daten abdeckt, müssten pro Microservices mehrere Spalten hinzugefügt und NULL Werte zugelassen werden.
Ein Beispiel für Punkt 2 wäre ein Microservices, der das Thema Bezahlmethoden abdeckt. Anfangs gab es beispielsweise nur Kreditkarte und Kontoeinzug. Dann folgte Paypal. Und kurze Zeit später dann Bitcoin. Der Microservices hätte hierzu mehrere Tabellen, wo er die individuelle Daten für die jeweilige Bezahlmethode halten würde. In oben gezeigter Aggregationstabelle müsste aber für jede Bezahlmethode, die der Kunde nutzt, eine Spalte gefüllt werden. Wenn er sie nicht benutzt, würde NULL geschrieben werden. Man merkt schon: Das stinkt.
Ein anderer Ansatz ist da deutlich besser geeignet. Welcher das ist und wie man diesen technischen realisieren kann, könnt ihr im GitHub Repository von Particular nachschauen.
Mit Tag(s) versehen: Clean Code, Patterns

Ich verstehe schon, das dass hier ein Werbe/Marketing Post für die Schulungen auf der angepriesenen Github Seite sind…..
Aber man disqualifiziert sich selbst, wenn man hier von Microservices u.Ä. spricht und in der Schulung werden als erster solche Monster wie MSMQ, DTC, SQL Server installiert….
Das passt alles nicht zusammen, das sollte man in der Zwischenzeit gelernt haben….
ok, die Diskussion dazu kann Bücher füllen, schon klar…
lg
Werner Mairl
LikeLike